Big Data
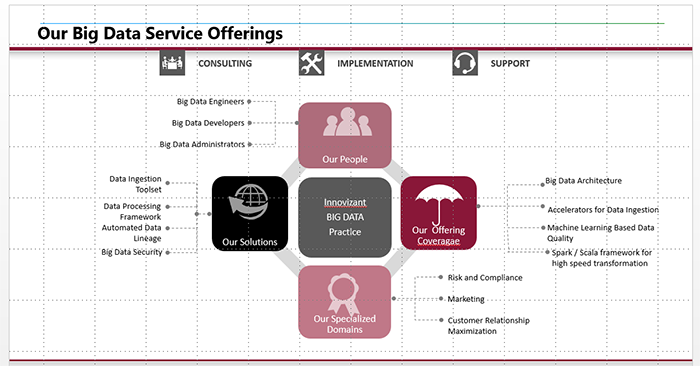
At Involgix, we have built a Big Data practice around financial services with seasoned professionals who have years of experience in the Architecture, Design and Agile Build out of Data Lakes for large banks and insurance companies. Client’s derive value through our organization from experience related to designing and implementing up to date Big Data architecture. Familiarity of deployment on premise, in the cloud or a hybrid infrastructure configuration have been executed successfully through our team approach.
What is Big Data?
Involgix’s view of Big Data encompass all forms of data available to enhance organizations ability in decision making. Customers, suppliers, competitors, regulatory bodies, fraudsters and criminals, internal employees all generate vast quantities of data that can today be harnessed and scaled for improving revenue, cutting costs and managing risk.
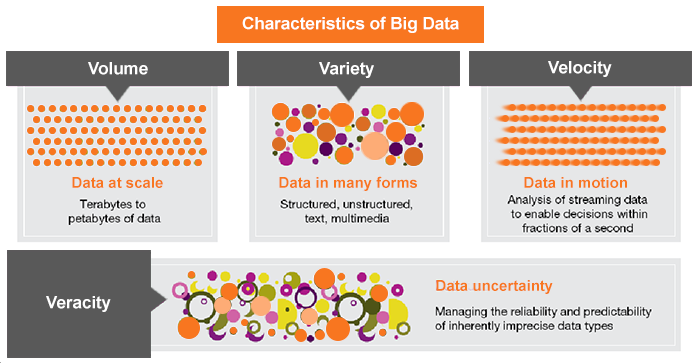
Banks, Insurance companies, new Fintech companies are all moving to establish and harness Big Data platforms this decade. Aggressive actions into Artificial Intelligence on Big Data is where institutions are investing to compete.
Why Involgix?
Involgix brings together years of industry experience in Big Data Ingestion, Management and Analytics with certified Cloudera, MapR, Hortonworks consultants and Hadoop contributors who provided LAR We provide you with:
- Hardware selection, sizing and configuration of your big data cluster
- On premise and Cloud based architectural solutions
- Automated Ingestion Tools and Assets for importing data from various internal and external data source systems
- Large Scale machine learning based proprietary data quality techniques
- Metadata management, security and lineage from sourcing to usage
- Management of complex data types from legacy systems to big data platforms
Involgix Strategy and Architecture Capabilities
Involgix’s unique and proven Architecture uses Spark as the base processing engine in tandem with Kafka and mimics a flexible Lambda like architecture for automated sourcing, ingestion and delivery of data to the Data Lake and into downstream warehouses such as Teradata. The snapshot below illustrates the various technology components, process flows, and a high-level data integration design. It is important to understand the Data Ingestion, Processing, and Storage zones in this logic.
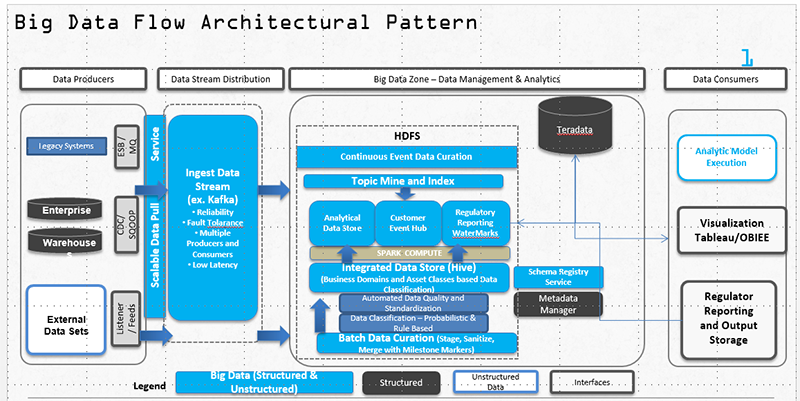
We have established a standardized set of use cases base on our experiences at several clients. The common big data use cases are:
- Registering data sources as they become available for ingestion
- Provisioning of data in the Data Lake for consumption
- Consumption patterns of data from the lake
To that end we have established standardized assets to accelerate your big data flows such as shown below. These accelerators enable data storage within the data lake at orders of magnitude than traditional systems.
Involgix’s Big Data Infrastructure Based Offerings
Involgix Big Data Infrastructure Professional Services helped clients across industries stand up their Cloud Based Infrastructure, On Premise Infrastructure and also Hybrid infrastructure. We have provided initial sizing for types of Big Data Installations, assisted clients in choosing the right environment to fit their needs taking into accound security, PII/Non-PII data, costs and efficiency based on their analytical and target spend.
Involgix has experience in all these leading Big Data Cloud Service providers with experience installing, configuring and deploying large scale cloud solutions for our clients.

Involgix delivers post – installation support, administration, monitoring with tools such as Ganglia and Dynatrace.
Involgix Big Data Ingestion Methods
At Involgix, we have developed a true “one size fits all” framework to source, extract, ingest and make available data from disparate formats, sizes and frequency. We have honed the framework at several large clients that leverage petabytes of data and proven the framework for adding new data sources as they arrive and ingesting data at near real time speeds.
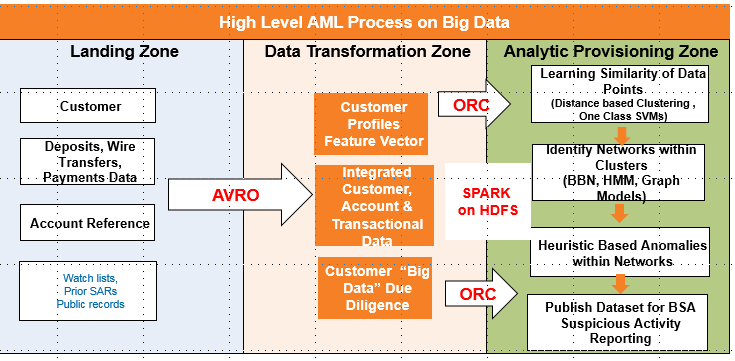
An example of how we use our Big Data Patterns to solve an Anti Money Laundering challenge is illustrated below:

Our Expertise
- Cloud Strategy & Implementation
- DevOps and Quality Eng. Services
- Data Science & Big Data
- AI Management Consulting
- Advanced Analytics
- Custom Application Design
Target Industries
- Financial Services
- Healthcare
- Retail Services
- Insurance
- Automation
- Telecom & Media
Technology Platforms
- Cloud Computing
- Enterprise Applications & Solutions
- Salesforce Development Services